
This is Why Every Developer Should Understand the Raft Consensus Algorithm

Imagine a scenario, you are working in a big e-commerce platform and the biggest sale of the year is going on and various limited stock products are getting a ton of traffic. Now as you know every distributed system is built with multiple servers working together, and it is not a big deal to encounter a machine failure or a network split.
Coming back to our e-commerce biggest sale situation and a server crashes, now for a specific product, server A thinks 5 items are left and server B thinks 7 are left and both accept the orders simultaneously. This will lead to Overselling leaving to angry customers with broken trust. This is the classic split-brain problem, when distributed systems can’t agree on a single truth.
To ensure that these chaotic situations never happen, we use consensus algorithms to maintain data consistency across all the servers in case of any crashes. While there are many consensus algorithms such as Paxos, PBFT, PoW to name a few, the consensus algorithm I will be discussing today is The Raft Algorithm. But before that let us look at what are the core challenges we face in a consensus algorithm.
The Core Challenges of Consensus
While at first it may seem a simple task to implement a consensus algorithm, but as we try to implement them we get to know that the challenges are real. It is like trying to get a group of friends to pick a restaurant over a spotty phone call where some phones die mid-conversation. Some core challenges of consensus are:
Leader Confusion – The situation in which two servers think that they’re the leader, they can accept conflicting client requests. Example: two checkout servers both confirm the last item in stock leading to overselling.
Node Failures – There are situations where servers crash, restart, or get partitioned from the network. But the system must keep functioning without losing confirmed transactions, which can be challenging.
Consistency Guarantee – There can be system failure but the users shouldn’t see different truths. If one server says “order confirmed”, no other server should say “out of stock.”
Without consensus, distributed systems can easily drift apart, and chaos follows. Raft solves these issues with a clear model which is electing the leader, then replicating the existing log , and afterward safety. Let's discuss them in detail.
How Raft Works?
We have discussed the problem scenarios where the consensus algorithm excels. Now let us understand the working of the Raft algorithm. The first part of its working is the Leader election.
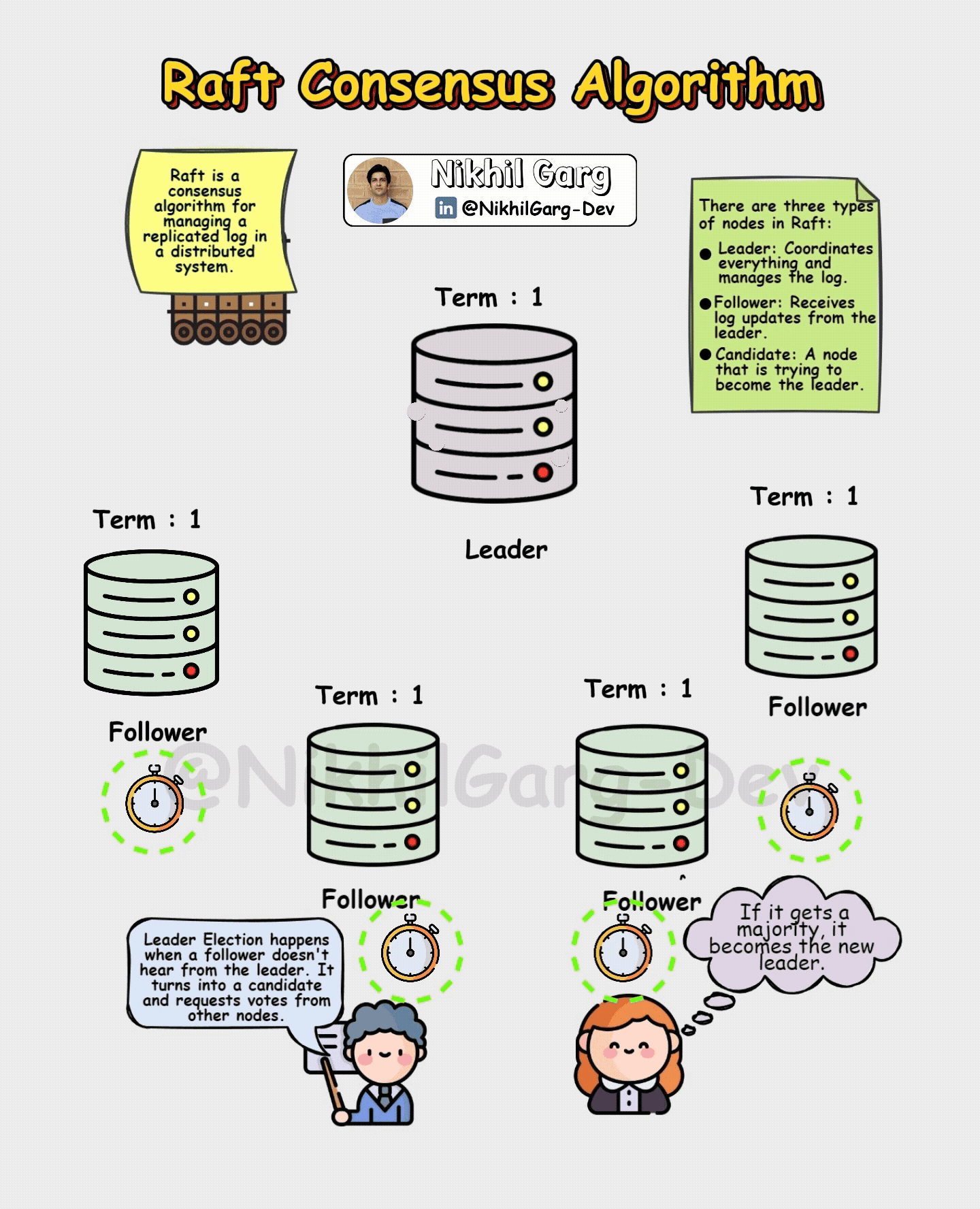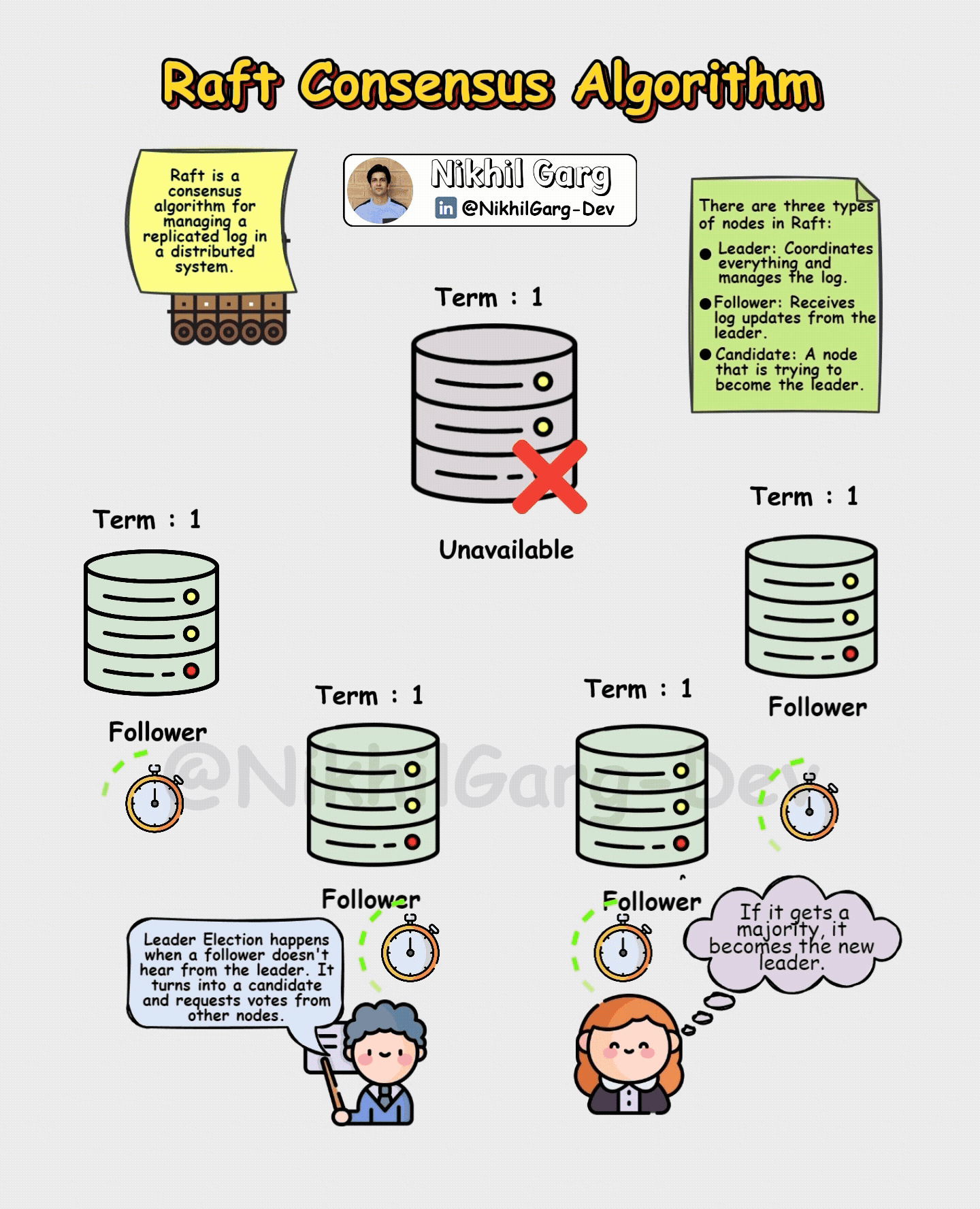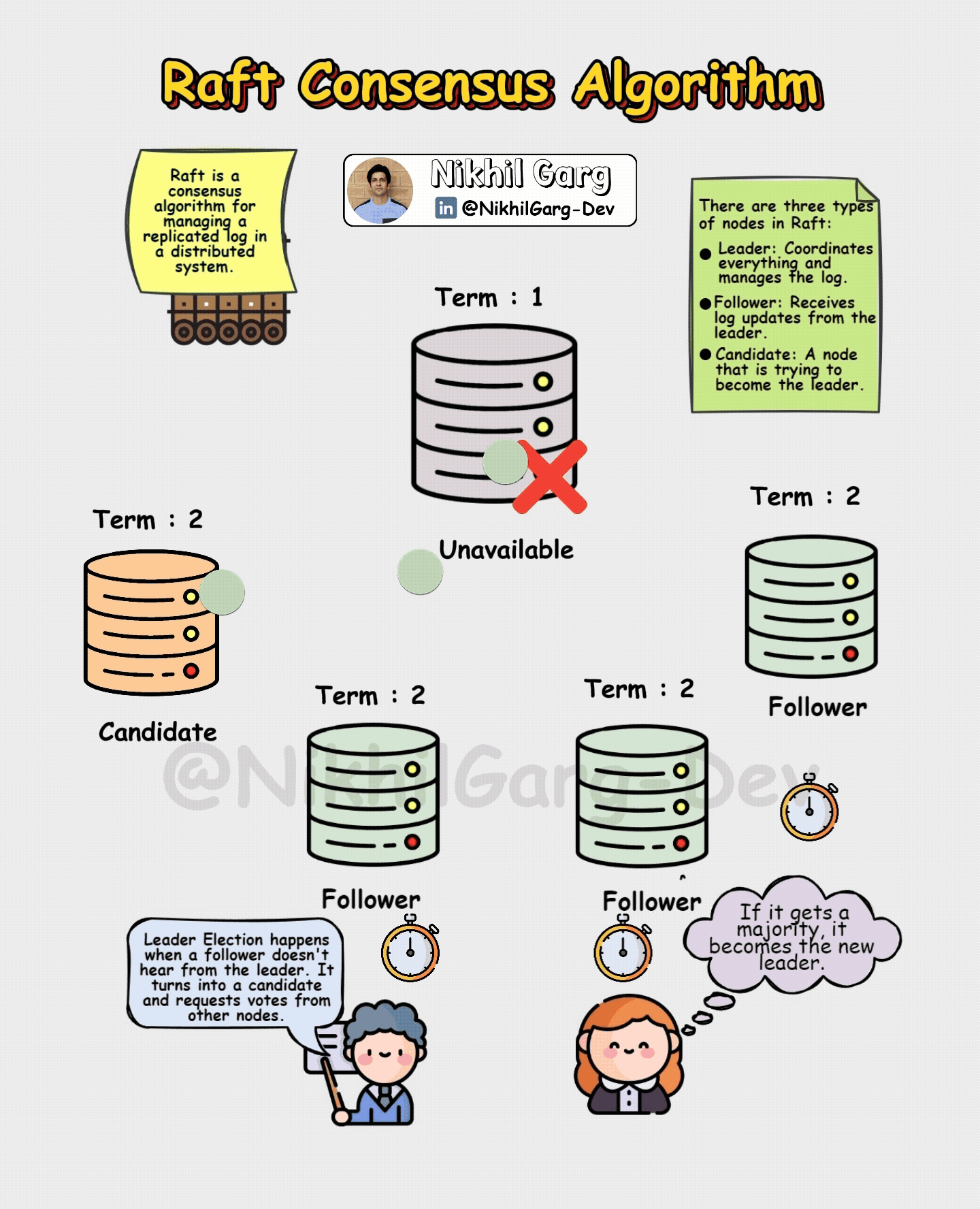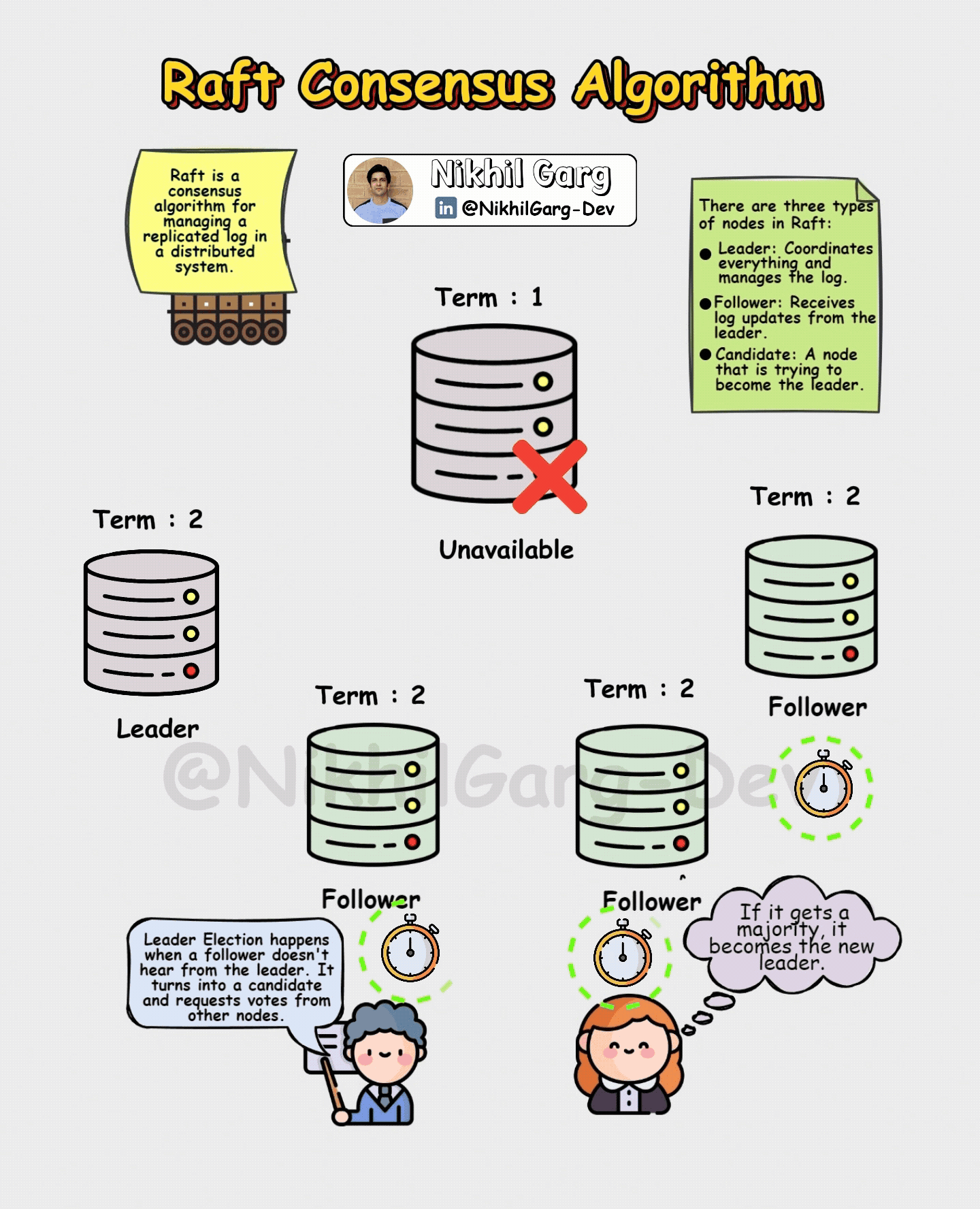
1) Leader election:
In the process of electing a leader initially every Raft cluster starts with nodes as followers. If a follower doesn’t hear from a leader within a certain time limit which are also known as heartbeat messages (for ensuring the health and status of other nodes), it becomes a candidate and requests votes from others with certain conditions such as
Each node can vote once in a term.
If a candidate gets a majority vote in the election process it becomes the leader.
The leader then starts sending heartbeat messages to reassure followers.
This will ensure that there is only one leader at a time, preventing split-brain.
2) Log Replication
Once a leader is chosen, now it becomes the single entry point for client requests. And the log replication process now can go seamlessly. Let’s say a customer buys a product. The request flows like this first the Client sends a Place Order request to the leader. Leader then appends this as a log entry. Then the Leader shares the entry with all the followers. Once a majority confirm, the entry is committed. The leader applies the order then responds “Success” to the client.
This majority rule means even if a minority of servers fail, the system still agrees on the same sequence of events.
3) Safety & Consistency
But there may be a scenario in which the leader crashes mid-process? For cases like these Raft ensures that there are no inconsistencies in the data. It does that by making sure that only a node with the longest, most up-to-date log can become the new leader. This prevents older nodes from undoing already-committed entries. And if there are followers that are lagging behind, they are brought back in sync by the new leader. So even during failures, Raft guarantees that there are no double leaders which avoids the split-brain problem, and that there are No lost confirmations such as a committed order that will not vanish in case of a crash.
Trade-offs & Considerations
As no algorithm is perfect and every algorithm has its strong as well as weak points, Raft is no exception. It makes certain trade-offs to stay simple and reliable. For example, raft focuses on data consistency and partition tolerance over availability, what it means is that raft will rather stop taking new requests than take the risk of conflicting data. It is also very simple to implement this algorithm and is very reliable in what it does. However, it makes certain trade-offs to stay simple and reliable. Understanding these will help you know when to use Raft and when it might not fit.
Let’s talk about the limitations of the raft algorithm:
Majority Required – Raft needs a quorum so let’s say in a 5-node cluster, at least 3 must be alive to make it work. But if more than half fail, the system will halt.
Latency in Elections – If a leader fails, clients may have to wait until a new election finishes. So in mission-critical apps, this pause can hurt UX.
Network Costs –With each entry requiring replication and majority confirmation, the process becomes slower than just writing to a single machine.
Conclusion
While wrapping up this article we can say that consensus is one of the hardest problems which we face in a distributed system. And Raft solved it not by being more complex, but by being more approachable. That’s why it became the go-to choice for engineers which work hard to build resilient infrastructure.
So the next time you launch a Kubernetes pod, discover a service with Consul, or secure a secret in Vault, remember that there’s a Raft cluster silently making sure every node agrees on a single truth and maintaining consistency throughout the system.
In distributed systems, failures are guaranteed but achieving consensus through Raft is how we turn chaos into order.